
The Wild West of MLOps
Your title don't mean nuthin' here pardner

The new meme on the block is MLOps. It’s a chimera of Machine Learning and DevOps that aims to develop tools and best practices to deploy Machine Learning models in production in a continuous and auditable manner.
Executive all over the world caught up in rigorously defining the ontological taxonomy of Machine Learning, Data Science, Deep Learning and Artificial Intelligence have now switched their attention to productionizing Machine Learning.
It’s time to delete those PowerPoint presentations with “Data is new the oil” and replace them with “Modeling is the easy part”.
Architects, Executives, Marketers and Venture Capitalists all beating the drum of the same story
Machine Learning model sizes have exploded. Who doesn’t love an exponential curve?

Machine Learning solves everything from climate change to economics to drug discovery. Queue a slide with a robotic blue brain

There is an abundance of players in the MLOps space. This spreadsheet by Chip Huyen usually elicits: “wooow there are so many MLOps startups” followed by “welp I guess I’ll get back to whatever I was doing before I saw this spreadsheet”

4. A smug remark on how “Modeling is the easy part” followed by a long explanation of how database management systems work
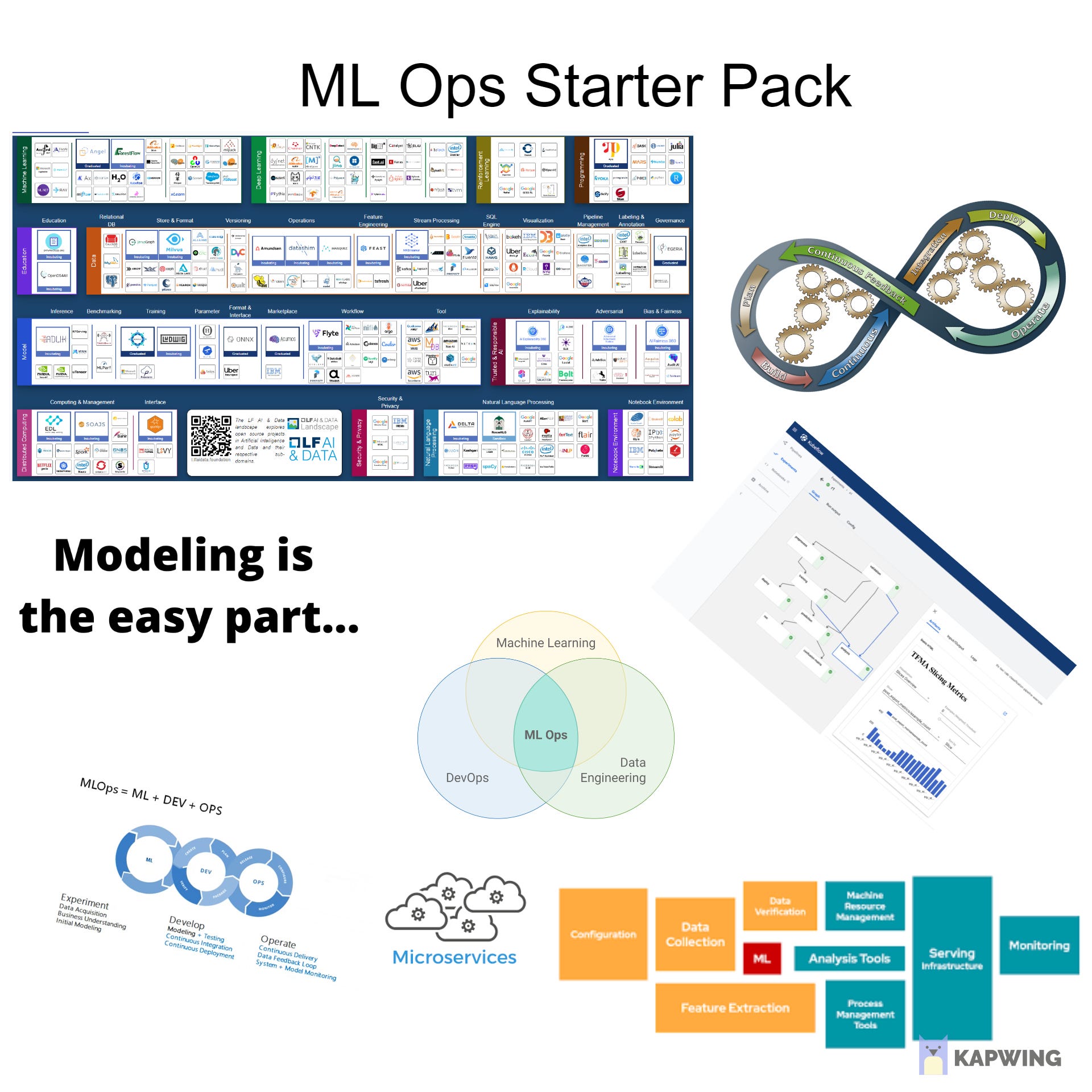
Concluding with a pitch for a product with a contact us form (pro-tip: companies with contact us forms either don’t have a product or need a salesperson to convince you that the product is good. What you want to see is a library you can pip install and a Github README)
But how can you tell whether an MLOps company is useful or not? What are the incentives that govern this space?
Machine Learning is all grown up
Welcome to the Wild West of MLOps son
Your title don’t mean nuthin’ here

Carrot Stack
So let’s say you build a new Distributed Training framework called make_fast. You support RPC, OpenMP, MKL and partner with every single hardware and data center manufacturer to provide first class support for your ops for real world training. 5 PMs all working together on the big blog post touting the biggest and baddest distributed training framework.
But then a more charismatic open source developer notices the make_fast library, adds a simple wrapper around it.
What’s more valuable make_fast or make_faster?
So the answer is it depends, in most cases make_faster is actually more valuable, they are getting the customers, the feedback, the press, the applications.
However, if you’re one of the few cloud providers in the world you can always hedge. If make_fast is more popular than make_faster great! And if make_faster is more popular then make_fast well they still need to run on some cloud infrastructure so also great!

A lot of software platforms upon closer inspection are simply a set of best practices and it’s really hard to build a moat around best practices especially if they’re open source.
I’m not particularly bullish on companies that make AWS easier to use like HashiCorp’s Terraform since AWS can sit back, see what wins out and then just copy it exactly or just hire the most useful people from that startup and double their salary.
Now let’s say your service is just called by some other orchestrator then where does the value accrue? This is a bit harder to predict but I figure that because people will spend more time interacting with the orchestrator then that means your service will become just an API call and that you’re dependent on the orchestrator for everything.
It’s been challenging to build moats around ML design patterns for this very reason. Some ideas are generally good like pipelines for BI processing or callbacks and without any patent or secrecy every deep learning framework ends up adopting all of the best ideas so the value doesn’t accrue to the creator by design in open source.
Traditionally, valuing businesses has involved capturing a moat that can sustain value for long periods of time but the new moat in the age of ideas is speed, if you are producing an overwhelming amount of new carrots, features on top of open source, then it’s difficult for anyone to keep up.
In MLOps treat your moat like quicksand
Listen to your elders
What have production ML teams been doing this whole time? Ok listing them out configuration management, data collection, feature extraction, Serving, process management, analysis, lots of 9’s, alerting and monitoring.
Sounds just like the traditional BI (Business Intelligence Stack) stack! Slowly we rediscover feature stores, schemas, cubes, distributed queues, caches and load balancers. But now they work with Machine Learning!
My first job out of school was as a Product Manager on the BI infrastructure team at MSFT. I was surprised the first day that I joined that I wasn’t on a Machine Learning team, I bitched and moaned and ultimately lost out on a bunch of valuable context because 8 years later, I now work on MLOps and I can hardly tell the difference between the BI world and MLOps world.
The companies that won in the BI world will also win the ML world
An ML model is essentially a microservice managed by some centralized team and the only real difference from an ops perspective is that the service takes more time to initially create and it rots/drifts so yeah monitoring is important. But fundamentally nothing changes.
But still if you’re serious about influencing the ML tech stack then going full stack gives you more control over your destiny. Partnering does have significant advantages to bootstrap but it’s easy for the relationship to devolve in adversarial manners unless the business models of companies are completely tangential to each other which in the case of data they rarely are.
Convincing an NVIDIA PM to support 8 bit quantization will likely go through several prioritization meetings where you rank the importance of your asks on a scale of 0-2, lots of back forth, not too much transparency. Again being in control of your own destiny lets you innovate more quickly after putting in an initial up front cost. The cost is mostly talent so as long as you’re paying as well as FAAMG (Facebook Amazon Apple Microsoft Google) then you can theoretically bootstrap any technical effort you want.
One Dashboard to Rule Them All
In the case of companies like Weights & Biases or ClearML, their play is really about providing as much as value as possible with 0 configuration. So your existing console logs, configs, Tensorboard dashboards (commonly known as Artifacts) all get logged with just a single line of code into a single authoritative dashboard.
Today, Artifacts can help you snapshot and roll back to previous models after a regression, they can give more confidence to auditors that a specific model was indeed responsible for a specific inference.
That dashboard then becomes an orchestration point for you to manage experiments with a single click, run inferences, they could even use something like Kubeflow but because people would come to their dashboard then they again have the most direct interaction with their customers.
The ML dashboard will be an operating system
Watson, Azure, Data Robot all have their own managed platforms, one place where you can go for all your current and future ML needs. Till death do you part.

But those companies haven’t captured the hearts of the open source community and a new integration still requires a top down partnership as opposed to just some dude on Twitter writing the integration over a weekend.
1 PM and 2 Devs per integration doesn’t scale
A company like Google could then respond with a managed offering to show your Weights & Biases dashboard within the GCP console itself, at first talk about integrations and collaborations with partners while simultaneously funding a PM to build out the exact same offering and eventually cut out the Weights & Biases logo.
Embrace Extend Extinguish is the MLOps playbook
This is a bitter pill to swallow but one thing smaller companies have been doing better than larger ones is building a sense of community and that is a moat albeit a more nebulous one.
Insurance > Risk Models
Azure as data breach insurance - Azure medical cloud is a separate offering that takes responsibility for leaked medical data on behalf of healthcare companies. That’s a pretty big burden to remove from customers.
That said, Azure is not creating two separate products one that’s insecure and one that’s secure for medical data. They are taking a contractual liability because they believe they can manage the risks of a medical data breach.
I only wish interpretability startups would have the courage to do the same.

If regulators insist on having ways to interpret Machine Learning models, the ML community will comply and respond in kind with useless techniques that aren’t used by anyone who understands them or understood by anyone who uses them. (the nice wordplay is by Zachary Lipton)
Vendors of solutions for interpretability, explainability, bias detection all miss a crucial point. They are selling risk models instead of selling insurance.
If you truly believe SHAP, perturbations, saliency maps, Bayesian thinking actually help make model decisions safer and more interpretable you should show some skin in the game. Start an insurance company, charge customers a premium depending on their industry risk, audit their models regularly to minimize risk of harm and if harm does occur, you better be the one testifying in front of Congress.
Like the plumber who points out leaky pipes without fixing them or the car manufacturer that doesn’t take liability for crashes caused by their auto-park feature.

Lindy Languages
Since 2012, we’ve been met yearly with a new UI library that makes everything simpler. I like to remind people that ML is a drop in the bucket relative to web development. The most popular project on Github is Vue.js which markets itself as an easier version of React.
So you wanna run a hello world? Download half of npm, learn these 3 build systems, sling 4 languages at once.
No thanks I’m doing just fine being mediocre at a single language.
JavaScript is not going away either despite a collective distaste for the language designed as a hack. You keep building layers on top to make it faster and the more you do that the more likely the language is to stick around.
But I hear you hear say: “Mark, many popular languages have died, why wouldn’t Python, C++ and JavaScript eventually share the same fate?”
It’s unclear to me if a popular language can ever die with the internet, the network effect is strong, people can share tips and tricks and build abstractions on top of a language to better handle its quirks.
Python doesn’t have a great type system but it’s mitigated by new type annotations which fit into a huge existing ecosystem, solves a real problem without asking you to go learn the quirks of a borrow checker.
I relearn JavaScript every couple of years and I’m kind of sick of it. Instead I now advocate for Rich, GradIO, Streamlit and manim depending on the specific usecase. They all make me feel smart.
In particular one thing I really like about GradIO is the way they mapped a function from inputs to outputs in a way that maps exactly to the way neural networks have a forward function from inputs to outputs.

Vendors of Complexity
Many startups I worked with that were acquired by Microsoft ran their entire backend on a single SQL database which they kept scaling vertically. Scaling horizontally is complicated because distributed systems are hard, using microservices to abstract away hardware and elastically scale is a great idea in principle but is also terribly complicated to get right.
It’s better to scale horizontally or use microservices after finding product market fit
Most startups dream of one day achieving the success of Google or Amazon so there’s a memetic bias to cargo cult everything they do while neglecting the timeline. Facebook was popular before it hired Yann LeCun.
Scaling infinitely to millions of users is something you only need to worry about after finding product market fit. As a good rule of thumb if your headcount is roughly one engineering manager per microservice you want to develop then microservices could be helpful but otherwise stay away!
Stack Overflow ran their entire business on 8 MySQL servers. But for some reason you need to get ready to scale to the entire planet by building on top of the Kubernetes ecosystem. Unless you’re an enterprise focused company building tooling for Kubernetes customers (which I’m guessing you’re not), probably not the best use of your time to go all in on Kubernetes.
Complexity is the engineer’s disease.
From Research to Blogpost
A well known secret in ML industry is that most ML efforts act as PR stunt which help garner funding to work on problems that actually matter.
That’s not because ML doesn’t work but because it really struggles with the tails. My favorite example was from my Microsoft days. Suppose you’re trying to parse out flight information from email and show nice useful cards to your users, you get 99% accuracy, you’re super happy, you start eying that promotion but then you get a furious feedback email in all caps: “YOU ****, YOUR STUPID AI ****** MADE ME MISS MY 9AM FLIGHT TO FIJI. IM MISSING MY WEDDING BECAUSE OF YOU !!”.
So whenever you’re trying to deploy a high value ML powered experience to your users, you need to explain that your app isn’t perfect which is hard. “Infusing” AI has been a challenge in products outside of search and relevance.
So instead it’s easier to make beautiful awe inspiring demos that don’t need to deployed to production hence the cynical subtitle: Research to Blogpost.
One company stands out in executing this strategy in a masterful way Open AI and their recent foray into investing in AI founders makes tons of sense.
Cool Research -> Cool Blog posts -> Media attention -> Get loads of applicants -> Fund best applicants -> Cool Research
This is a very powerful feedback loop straight from the Y-combinator playbook.
Until we figure out how to scale Open AI, all we have is a cold war with inflatable tanks

We had our fun, we built lots of cool demos, now we need to start building products that people use.
Everyone wants to be a “platform” and defer talking to actual end users. There are exceptions like Descript which lets you video edit over your podcast transcript instead of your podcast waveform or PictureThis which helps you learn about plants on your walks.
Labeling
The ministry of truth is here but it’s invisible, underpaid and no-one likes it.
Waiting for labels sucks, finding incorrect labels sucks even more and writing unambiguous instructions that would actually get you the intended label you’re looking for - well that sucks the most.
The mechanical turks running the tail of Machine Learning all work in the same call centers

But labeling is comforting, if you have labels then you have a supervised learning problem and with enough data then your business problem is solvable. So there will continue to be a niche for data labeling like scale.ai startups to make it easier to manage relationships with labelers, data quality, a slick UI but all of them suffer from the exact same problem Tinder does.
Winning Tinder means finding the love of your life and getting off the app where you can’t be targeted with ads. Similarly labeling can help you kickstart your ML efforts but when you’re big and successful and everyone wants your attention then you’re better off creating your own labels in a self supervised manner (SSL) because labelers simply cannot scale to millions of users.
Labels aren’t even a good strategic moat, all someone needs to do is find out where you got your labels done and send them a nice check.
As an example Tesla can run full self driving (FSD) car predictions in the background and see where their predictions differed from the driver. So you get a nice feedback loops and an actual moat. (Nit: The moat isn’t real if sim2real works)

With a similar drawing you can figure out why Bing never caught up to Google despite some of the smartest people in the world trying their hardest to turn “Bing it” into an everyday expression.
As a user I don’t care about what algorithms Google search use, all I care about is that their initial search product is good enough and if it is they can use my click data to fine-tune their search and set themselves up with a trillion dollar moat.
This paper is great except for the below section which sounds eerily similar to Bill Gate’s supposed comment that 640KB of RAM is all anyone would ever need.

So before you can get self supervised learning with this nice sort of feedback loops it seems like you need product market fit first.
Language vs Compiler vs Hardware
It’s unclear whether ML models will slowly converge to a few key architectures or whether new kinds of architectures will constantly emerge.
For Hardware Accelerators the best outcome is a few architectures win out so they can optimize for a select subset of ops. What it comes down to is how many transistors you can fit on a circuit board and what price you were able to negotiate with TSMC. The bigger you are the better looking your sales team will be and the better your deal with TSMC will be.
So how do you compare different architectures? The first is “FLOPS per dollar” which is one reason why NVIDIA refuses to increase their prices even though their GPUs are constantly sold out. And the other is end level task performance on standard benchmarks like mlperf which include among other things MLP, CNN and transformer benchmarks - the Lindy architectures of Machine Learning. If you’re not on mlperf you are essentially signaling to your customers that they need to do be doing your benchmarks and that conversation never goes well.
Compiler writers want to maintain the peace by keeping a small subset of ops so they do things efficiently like operator fusing to avoid unnecessary memory reads, automatic quantization since we keep pushing lower precision numbers for inference.
If the subset is small then hardware manufactures are happy because they have less ops they need to translate to work on their hardware but at the same time it becomes more and more likely that when a user runs a program they get an unsupported op error or worst a silent slowdown like on TPUs.
If the subset of ops is large or changes frequently then users are delighted, everything they care about is being sped-up but hardware manufacturers are constantly having to race to keep up.
As of today, even though network are architectures are converging to Transformers and Resnet - ML Engineers still have more leverage than Hardware Engineers because user facing libraries rarely get broken but backend ops constantly do.
If you want to figure out who has more leverage in a relationship, look at who can break backwards compatibility first

Conclusion

Does democratizing mean more people have access to a technology or more people can create it? Depending on what you believe, it may not be that important to create a distributed training model training framework for the masses.
Growth of ML in production is predicated on ML becoming more and more useful. For large successful companies with product market fit that generate a seemingly infinite amount of data, almost all MLOps tools will be useful. However, it remains to be seen whether Machine Learning in of itself can help a company reach product market fit.
So if you run a consumer oriented MLOps tool you need to help more people create valuable businesses with ML as a key strategic component. You can’t escape turning into an EdTech or VC firm. The bigger the pie, the bigger your share.
Democratize Product Market Fit before democratizing Machine Learning

Epilogue
I’ve been asked to expand more on insurance companies for Machine Learning. In my mind this is the most overlooked business opportunity in Machine Learning so it feels like a follow-up blog post would be appropriate.
An area I didn’t expect to get so excited about has been prompt engineering. After using Copilot and CLIP I found that there were lots of tricks to make them work well. Playing the Synth isn’t really playing an instrument but it sounds cool. And fine-tune when prompt engineering isn’t enough.
So make sure to subscribe to see the follow up post on Prompt Engineering: How to make it work and why it makes devs so mad.

Acknowledgements
Thank you to Daniel Bourke, Mazen Alotaibi, Hamel Husain, Woo Kim, Carlos Escapa and the Robot Overlord Discord Community for early feedback.