
Working Class Deep Learner
Tips from Mediocrates

You interviewed with DeepMind, this was your moment, you were told you’re a promising young lad.
You aced the first couple programming screens. “Kid you’re going places, you can work here for a year and I can set you up with a PhD at MIT”.
But for that last interview you stumbled on implementing vanilla breadth first search, spiraled into self doubt, blacked out and woke up remembering feedback like “you need more keyboard time”.
And that was it, your dreams of a life where you pursued your interest slowly evaporating. You begin to tell yourself that maybe you should follow your strengths and instead apply to ML engineering roles. You will learn about real businesses and solve real problems for real people.
For all the dreams you had with the confidence instilled in you by your loving mother you now realize that in a room you’re neither the smartest or dumbest engineer. You’re nice but not charismatic, you never got around to writing that book for Packt. Your belly is slowly growing as your metabolism isn’t what it used to be. You mostly keep your head down, you try to keep up with the buzzword du joure that senior management is pitching and keep chugging along on your PowerPoint presentation so that they could finally see the value you bring to the company.
You’re square in the middle.
New papers overwhelm you, new tools and languages make you fear your obsolescence. ML is growing like crazy but for whatever reason your salary has barely kept up with inflation.
If that’s you then this guide is for you, how do you manage life as a working class deep learner?

Working class Deep Learner
The world is changing and fast. The internet offers us a deluge of high quality content, our attention is finite and we naturally give it to the best of the best who capture most of the value from the creator economy.
But you’re average, you get roped into meeting after the next. You barely have time to code let alone time to invent libraries so you need to keep an eye out for tools that are becoming too important to ignore. Moving from AWS certification to the next.
You’ve been working with Keras and Pytorch models for a while now, it feels like a step up over Tensorflow 1.0. How are you possibly expected to setup a Tensorflow model if you can’t print Tensors.
So this seems like a step up, sometimes you’ll lurk on Twitter and see people all excited about Julia or Jax but you don’t have much free time for a side project and there is no way you’re convincing senior engineering leadership to port things to a new language. How would you hire people? Eventually natural selection plays out and you’ll find yourself porting your code base to use a new framework when your boss prioritizes it.
Regardless of the amount of hype that a new paper gets you wait about 2 years before reading any new paper, you figure that time is the best filter.
AI alignment, scaling laws, symbolism these are all topics best dealt by people who already have money or don’t care about money.
Matrix multiplication is all you need
How much math do you need to know for Deep Learning? There’s really one model you need to understand for now and that’s BERT. So let’s take a look.
Download a pretrained BERT base model from HuggingFace and print it.
from transformers import AutoModelForMaskedLM model = AutoModelForMaskedLM.from_pretrained("bert-base-uncased") print(model)
The first thing you’ll notice are the embeddings: there’s the word embeddings, position embeddings and token type embeddings.

These represent all inputs to a BERT model. A neural network doesn’t understand what a word or position or token type is so an embedding lets us essentially create a key value store to provide inputs to a neural network. If you do have some other data you’d like to feed, well it’s just another embedding and look at you on your way to becoming a researcher.
Embeddings are a key value store

The second major piece is the BertEncoder which is a ModuleList made up of 11 BertLayers where each layer has a self attention and output both made up of a combination of Linear Layers, Dropout and Layer Norms.
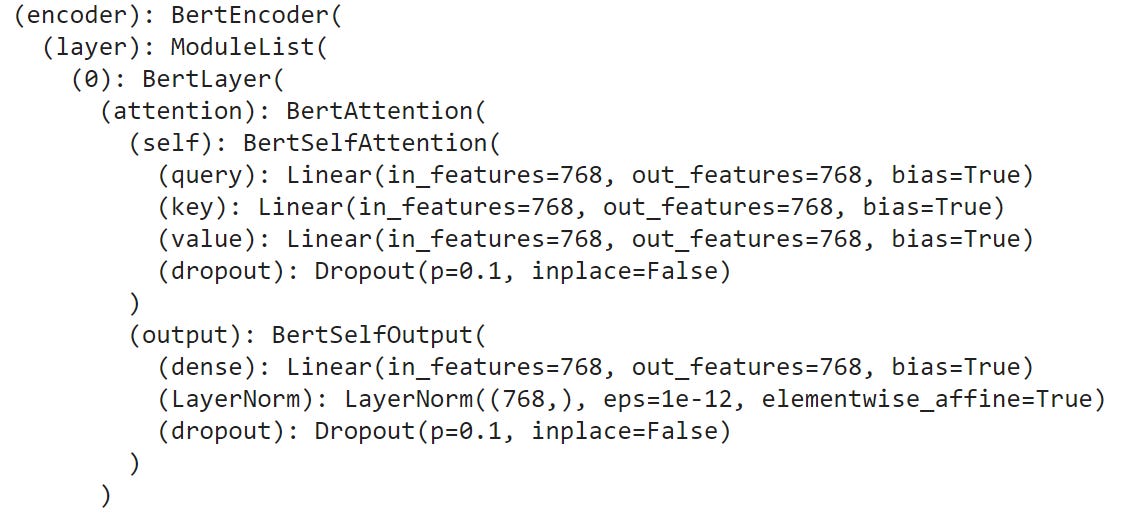
So what’s a Linear Layer exactly? A generalization of a line.
What about dropout? Flip a coin and zero out parts of the Linear Layer. What about Layer Norm? Well that’s just a way to make sure the activation across multiple channels aren’t too far apart from each other. A lot of effort in Deep Learning is dedicated towards making values not too small and not too big to avoid the infamous NaN. You’re not paid enough to think about properties of of various layers, just use whatever is popular.
Well I lied, knowing about convolutions also helps and turns out a convolution can just be implemented as a matrix multiplication.

What about RNNs?

So matrix multiplication is all you need is not just a meme. GPUs are matrix multiplication machines and that turns out to be very useful for Deep Learning.
ML compilers
Another choice you may have to make is which ML compiler to use. The idea is that for now lots of ML architectures are converging so you can use the best hand crafted kernels that giant internet companies and hardware vendors have created for you.
Compilers are kinda complicated, they’re written in C and sometimes even Haskell and it’s just a tough business to be in - not many ML compiler startups. But the benefit of a compiler stack is that it gives a chance for working class deep learners to actually utilize their hardware.
Which ML compiler should you use? Just benchmark and see. In case it wasn’t obvious, that’s a joke you’re not going to get time to run comprehensive benchmarks and even if you did there’s so many nuances like process isolation, cold starts, CPU fallbacks, benchmarking overhead etc.. so you can’t really trust your own benchmarks too much.
That said you do need to sound smart so you need to know at a high level which ML compiler tricks are useful or risk being replaced by someone half your age.
The most important tricks are:
Lower precision
Fusion
Batching
Lower Precision
Diving a bit deeper, using quantization has gotten a lot easier, all you need to know is Intel has some libraries to make int8 matrix multiplications faster so you just wrap your model and now it’s smaller and hopefully faster. (something about int8 hardware needing less silicon yada yada)
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
NVIDIA instead offers Automatic Mixed Precision Training and TensorRT which adds lots of fusion tricks (more on fusion next)
The trend of lower precision arithmetic is because Machine Learning isn’t scientific computing, precisions don’t matter too much at least not for all ops. For the ops that do matter AMP keeps the original precision. No worries if this sounds too complicated then just add a single line to your model inference and it’ll be roughly half the size and hopefully faster.
with torch.cuda.amp.autocast():
output = net(input)
Fusion
A typical MLP would look like
def forward(self, x):
x = F.relu(self.fc1(x)) # write x
y = F.relu(self.fc2(x)) # write y
z = self.fc3(y) # write z
return z
Which would store x, y and z in memory and then load them back. To avoid uncessary reads and writes back to memory or god forbid disk you could rewrite the below as a single operation and maybe even have hand-code a kernel function that does just this if this sequence of operations is important enough
def forward(self, x):
return self.fc3(F.relu(self.fc2(F.relu(self.fc1(x))))
Batching instead of for loops
Another more advanced concept you may need to consider is that again GPUs are matrix multiplication machines but they do much better if they need to multiply two large matrices instead of iterating over multiple smaller ones.
This idea is very familiar to the MATLAB community so as example from the Mathworks forum
You could rewrite
C = zeros(size(A,1),size(B,1),size(B,2));
for i = 1:size(B,2)
C(:,:,i) = A(:,i).*B(:,i)';
end
As
C = reshape(A,[size(A,1),1,size(A,2)]).*reshape(B,[1,size(B)]);
It generally helps to think of Tensors as data structures that can be manipulated with stack(), squeeze, unsqueeze(), reshape() to find ways of removing for loops from your numerical code.
for loops considered harmful
These are the main compiler tricks for numerical code but most of the typical kinds of optimizations you’d find helpful in C code are probably also helpful for numerical code.
Most compilers are in C++ and that alone is a high barrier entry for working class deep learners but there is hope: Compilers in Python exemplified with libraries like torch.fx can help a working class deep learner turn into an open source contributor.
Magic configs
As a working class deep learner you’re not going to be spending any time writing papers or inventing new algorithms, you’re going to take models that other people have trained and figure out how to deploy them. Improving accuracy is not your job, you’re worried about latency and throughput because you don’t want to keep fighting with your accounting department.
If you have the misfortune of being responsible for deploying a model to production, I’m sorry. To make sure that your web app isn’t absolutely miserable to use, you’ve had to maintain latencies of around 5ms and here comes your data scientist friend wondering why a 20GB model has a 1min latency on an Intel Core Pentium Duo.
You roll your sleeves and bust out some forbidden arcana from the Pytorch Docs.
torch.set_num_threads(1)
But why does that work? You just mumble something about threads contending with each other. But you look at your benchmarks suite and it’s still too slow.
That’s not the only magic config you need to worry about, there are so many and it’s impossible to keep up unless you run the performance optimization teams at NVIDIA or Intel so as an alternative each hardware manufacturer will usually have magic configs bundled up in a Docker image e.g: see TensorRT and IPEX.
But even after all this toiling, no improvements.
So as a next step you get a flame-graph.

You stare it for a second then remember you don’t really know how to read a flame-graph.
It’s to get a GPU but you really don’t want to fill out a PO. You try Google Collab but it keeps disconnecting, you try applying for Google Research grants but then remember you don’t have any interesting ideas.
You escalate to your manager and a few months later you finally have a fresh p3 instance on AWS. You spend the entire week learning how to install CUDA and after that masochistic exercise you still barely see any improvements.
nvidia-smi is your best friend

You’re looking for 2 things
You need to see a model loaded to the GPU (2072 MB in the screenshot above)
You want your utilization to be as close to 100% as possible (0% means you are paying NVIDIA to use an Intel CPU)
The easiest way to bump up that GPU utilization is to increase the batch size. At the very least try out all the powers of 2 between 2 and 2048. Why powers of 2?
For whatever reason NVIDIA GPUs like powers of 2 - see SO answer for more context. TensorRT likes powers of 8, again no-one expects you remember any of this stuff. It’s just magic configs that smart people will tell you about.
If even after increasing the batch size to ridiculous numbers you’re still not seeing any throughput improvements then odds are your CPU is loading data too slowly to the GPU or you don’t have the pin_device=True setting in your data loader which speeds up data transfers to the GPU by leveraging page locked memory.
It’s hard to figure out any of these from first principles so you mostly won’t, you’ll follow smart people on Twitter who will share their tricks, just copy them

Full Stack Working Class
Over the years you’ve seen teams invent and maintain worst versions of Kubernetes. However, you still can’t bring yourself to love Kubernetes. You remember a time when you could just write code, but over the past couple of years your job has turned into checking in YAML files into a Git repo or setting up a DAG in a Python DSL, pushing some buttons and hoping the K8 gods will give you visions of all green.
The end to end ML infrastructure in Kubernetes has slowly converged across enterprise shops. For training you would upload a training script, data, credentials and deploy them. Your script would chug along and save logs and persist the model weights to a volume. After that the same model weights are loaded by an inference pod which you could theoretically elastically scale if you had the usage.
The full picture is a bit more complicated, this what Kubeflow suggests as a reference architecture.

That’s a lot of nodes so do you need to know everything? It’s completely unrealistic that a single person can be an expert in all the above technologies and machine learning but that’s exactly what management expects because let’s face the headcount is still being negotiated. So you better be a team player.
If you do survive for more than a couple of months you can maybe get that promotion or start growing a small team. So what’s the best way to do this as a working class deep learner?
The output of most ML companies is exciting blog posts but let’s face it, your work on credit risk scores is boring.
Your angle needs to be scale. You need to run as many experiments as possible. Thousands of pods with slightly different hyperparameters need to be doing your bidding.
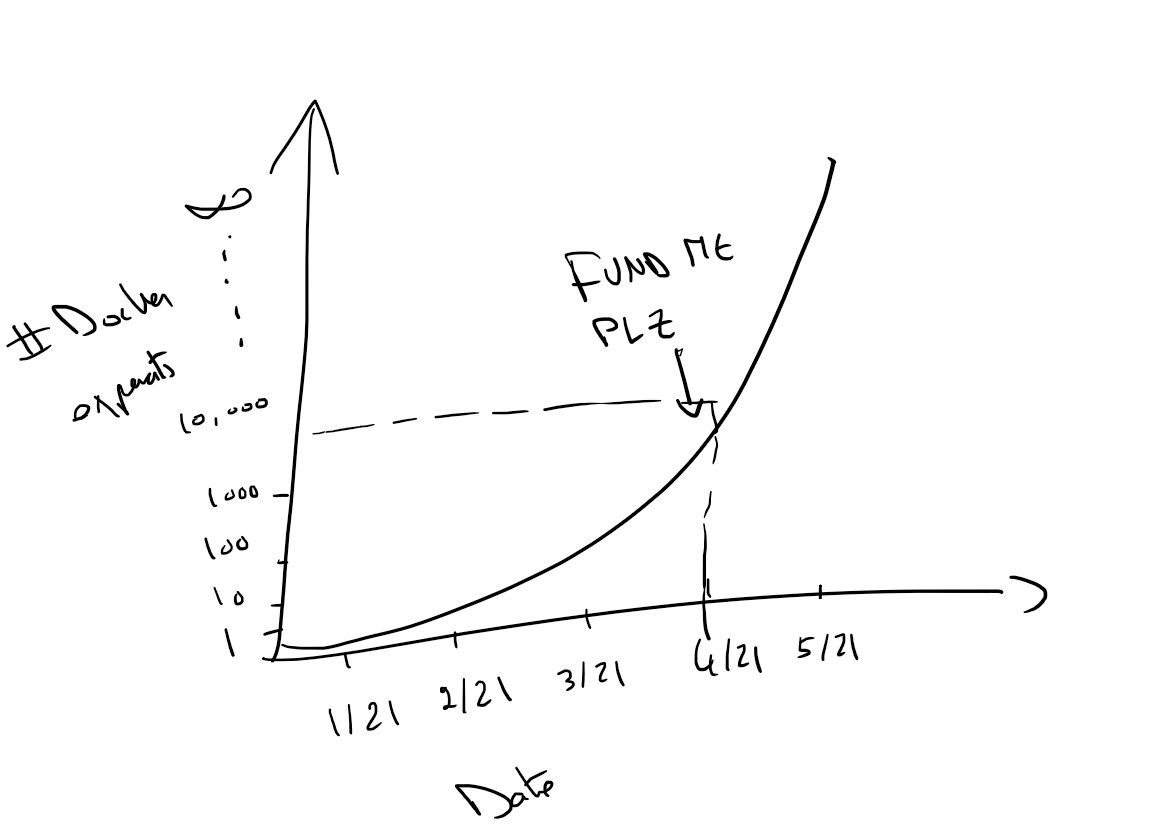
Machine Learning is an empirical science, your business value isn’t always obvious so you show your growth metrics to VPs. Do not talk to them under any circumstance until you can share a slide with the below graph.
Kubernetes has the benefit of being multi cloud so it gives you some insurance in case some cloud company starts to seriously out-innovate a competitor. So which cloud provider should you use?
Trick question, your sales department will decide for you. High level decisions by important people aren’t made with data, they’re a byproduct of relationships forged by years of good stories and firm handshakes. Your head of sales used to work with the head of sales at GCP, they still play golf together, they were able to sign a deal with a good discount along with an understanding that a service is down you can just call a Google rep and be really angry on the phone.
This will unleash a small army of solutions architects who want to quickly sync with you to better understand how they can help you. Ultimately for all the complexity cloud vendors want to sell you, there’s a few products that are worth understanding inside out.
Bench-marketing
The reproducibility crisis is problematic in academic papers but in industrial work it’s much more rampant because there’s a much stronger economic incentive to “fudge” the numbers.
Every hardware vendor is the cheapest, consumes the least power, has the most innovative design and runs BERT the fastest. Every dev tool is the fastest, has a modular minimal design, has the best community and most industry usage.
The golden law of benchmarks is if you can’t reproduce it, it doesn’t exist
And an addendum to the golden law for working class deep learners is that if you can’t confirm a benchmark in the 30 minute break between your two meetings, it doesn’t exist.
I can’t count the times when I’ve tried a new tool that’s “better” only to be disappointed after running a simple sanity check experiment. To the point where I can’t believe anything is true about Machine Learning unless I’ve tried it out myself.

The flipside of that is state of affairs is that I’ve become “boring”. I probably won’t have as many exciting conversations with researchers but I care more about being financially independent. I can’t get too distracted until I’ve made it.
In the meantime there are some smart people telling me most papers are wrong so I don’t feel bad about writing shitposts as a semi serious hobby.

On which timeframe do we expect people to finally start doing ML correctly? I would conjecture never.
The closest parallel is Statistics which has been around since the 1622 and people still get tripped up over all sorts paradoxes, simplifications and plain misunderstandings.
From the last chapter of Richard McElreaths’s fantastic book.

Your uncertainty and apathy can be an advantage, you can call it radical delegation. If you’re at a large “unsexy” company, vendors will do anything they can to make you happy and close a sale because you are the only one who can sway the accounting team.
This is one of the rare moment where you can be the Belle of the Ball.
For all the condescending comments you’ve heard from PhDs and professors toiling away on problems that nobody except their friends care about.
Remember…
Machine Learning is temporary but Freedom is forever.
Acknowledgments
Thank you to the Robot Overlord Discord community for inspiring me and Roon, Horace He, Andrew Carr and Ainur Smagulova for carefully reading my first draft.
"You spend the entire week learning how to install CUDA and after that masochistic exercise you still barely see any improvements."
10 years since ImageNet and you still have to download a PDF to install CUDA.
"Every hardware vendor is the cheapest, consumes the least power, has the most innovative design and runs BERT the fastest. Every dev tool is the fastest, has a modular minimal design, has the best community and most industry usage."
Haha
You know the product doesn't offer much when they tell you features not benefits.
Go to the homepage of almost any GCP or AWS service and every single one with tell you: scalable, zero-downtime, no servers and my favorite...
"networking capabilities for hybrid and multi-cloud scenarios"
What do any of these even mean?
Where can I run my ML model code?